This is the first post of a few on my approach to Aaron Courville’s Deep Learning class project of winter 2017 at UdeM. The goal is to do image inpainting conditioned on captions. See https://ift6266h17.wordpress.com/project-description/ for details.
After a first stab with GANs I decided it’d be more interesting to try Orderless NADE, an approach that me and mine also used for generative modeling of music (see this rejected ICLR submission).
Like NADE, Orderless NADE essentially models the joint of a multivariate distribution by factorizing it into a sequence of conditionals, providing distributions over one variable at a time conditioned on some other variables. With NADE, you’re tied to a single factorization; a single ordering over variables. Come sampling time, you sample ancestrally according to this ordering.
Orderless NADE on the other hand is trained to model all orderings simultaneously. Not in the lame way of estimating the expected gradient with a monte-carlo sample of a single ordering, but by sampling a whole bunch of conditionals from various orderings and training them all in one update. In practice, it means you apply a mask to the input to a convnet and have it reconstruct the masked-out variables.
The official way to sample from an Orderless NADE model is to uniformly choose an ordering and then sample ancestrally according to this ordering. We’ve found in our music work that this sequential process leads to crappy samples due to accumulation of errors. Instead we explored the use of Gibbs sampling from this model, basically repeatedly masking out a block of variables and resampling it using the ancestral process. This is super wasteful computationally, but much more robust as it gives the model the opportunity to correct itself.
Gibbs sampling from Orderless NADE has been explored before by Yao et al. (https://arxiv.org/abs/1409.0585), but with the intention of coming up with a faster way to sample, not a slower one. Yao et al. get the desired speedup by resampling the masked out block of variables mutually independently, i.e. in one shot. We’ve found that for music this still produces better samples than the original, ancestral Orderless NADE process!
My overall architecture is just a convnet mapping from image and mask to reconstructed image. The caption is run through a word-level Quasi-RNN for efficiency (I care more about speed than capacity because I think the caption is going to provide very little information anyway). The RNN hidden states are merged into the convnet through attention; every few layers, I do a dot product with a learned metric between the convnet featuremaps and the RNN hidden states to get a tensor of shape height * width * time indicating relevancies of each RNN state to each pixel in the featuremap. This tensor is run through a softmax to get weights for a convex combination of RNN hidden states to be added to each feature vector in the convnet activations.
Here are some animations of the Gibbs process arriving at a solution:










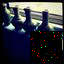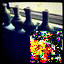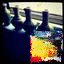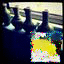









I seem to need to run the Gibbs chain for longer or to fiddle with the annealing schedule. Also it seems to be fond of extreme values (black, hard red/green/blue) which doesn’t really make sense as I’ve discretized the RGB values into 256 categories each; the endpoints are not special.
The code is at https://github.com/cooijmanstim/my3yearold.